Training LLMs in 2026
This is a quick note to summarize what I think are the main components of training a capable LLM in early 2026. These notes are primarily to organize my thoughts for myself. I’m putting them online in the hope that they may be useful for others.
My overall sense is that a few years ago there was a broad separation between “pre-training” and “post-training,” and that anything to do with “alignment” fell into the post-training box. But now, there seems to be a much clearer division of work between pre-training, methods that aim to improve capabilities that aren’t quite pre-training (which could be called capability shaping), and methods that aim to increase alignment (or alignment shaping). The divisions between these three areas are a bit fuzzy and the line may get blurrier over time, but here I’ll just expand on this preliminary division as a starting point for more detailed analysis.

Distinguishing Stages of Training
There are now many “recipes” for training an LLM that you want to perform well on one or several tasks. At a high level, we can identify a few features that help us to distinguish one part of training from another:
- Objective: The high-level optimization goal that defines what the training stage is trying to make the model do better.
- Data regime: The composition, scale, and structure of the data distribution used during that stage of training.
- Loss function: The mathematical function whose minimization (or maximization) defines how model parameters are updated.
- Output: The trained model artifact produced at the end of the stage.
- Resulting properties: The behavioral and performance characteristics the model exhibits as a consequence of that stage.
- Compute allocation: The fraction of total training compute budget (FLOPs, GPU-hours, or tokens processed) devoted to that stage.
Using these features, at a high level we can identify roughly three “big” stages of training an LLM:
- Pre-Training
- Capability Shaping
- Alignment Shaping
The relationships between these stages can be seen in Figure One above.
The “back arrow” in the figure indicates that the relationship between capability shaping and alignment shaping is not simply that alignment shaping consumes the output of the capability shaping step: often the process of aligning a model reveals that its capabilities should be augmented as well, leading to a kind of feedback loop between capability and alignment development.
Using the features listed above, these stages can be described as follows:
Pre-Training
- Objective: Learn a general-purpose next-token predictor over a broad distribution of text (and possibly code or multimodal data).
- Data regime: Massive, weakly filtered corpus; self-supervised learning.
- Loss function: Primarily autoregressive cross-entropy.
- Output: A foundation model with broad linguistic competence and latent world knowledge.
- Properties shaped: Syntax, semantics, factual associations, reasoning priors, and long-range dependency handling.
- Compute allocation: Dominates total training compute.
Capability Shaping
- Objective: Refine or expand specific capabilities without redoing full pre-training.
- Data regime: More curated, domain-targeted, or structurally modified corpora, often including code/math data and long-context examples.
- Loss function: Primarily next-token cross-entropy over targeted distributions, often through continued or domain-adaptive pre-training.
- Output: A stronger capability model prior to alignment optimization.
- Properties shaped: Reasoning depth, tool use, code ability, math performance, and long-context competence.
- Compute allocation: Usually a smaller but still meaningful share of total training compute compared with pre-training.
Alignment Shaping
- Objective: Shape behavior to meet human preferences, safety constraints, and interaction norms.
- Data regime: Human-labeled demonstrations, ranked outputs, and policy/reward feedback data.
- Loss function: Supervised imitation losses (SFT) plus reward or preference-driven optimization objectives (e.g., RLHF, RLAIF, RLVR, and DPO-style methods).
- Output: Deployment-ready assistant model tuned for interactive use.
- Properties shaped: Helpfulness, harmlessness, truthfulness, and instruction following.
- Compute allocation: Typically lower than pre-training, but potentially significant due to iterative preference and policy optimization cycles.
A Detailed Look at Capabilities and Alignment
Pre-training is a relatively easy step (conceptually, if not economically), but capability and alignment shaping are each growing in complexity as researchers find new ways to improve LLMs. As a result, we can “zoom in” to get a more detailed view of these latter two steps, as you can see in Figure Two.
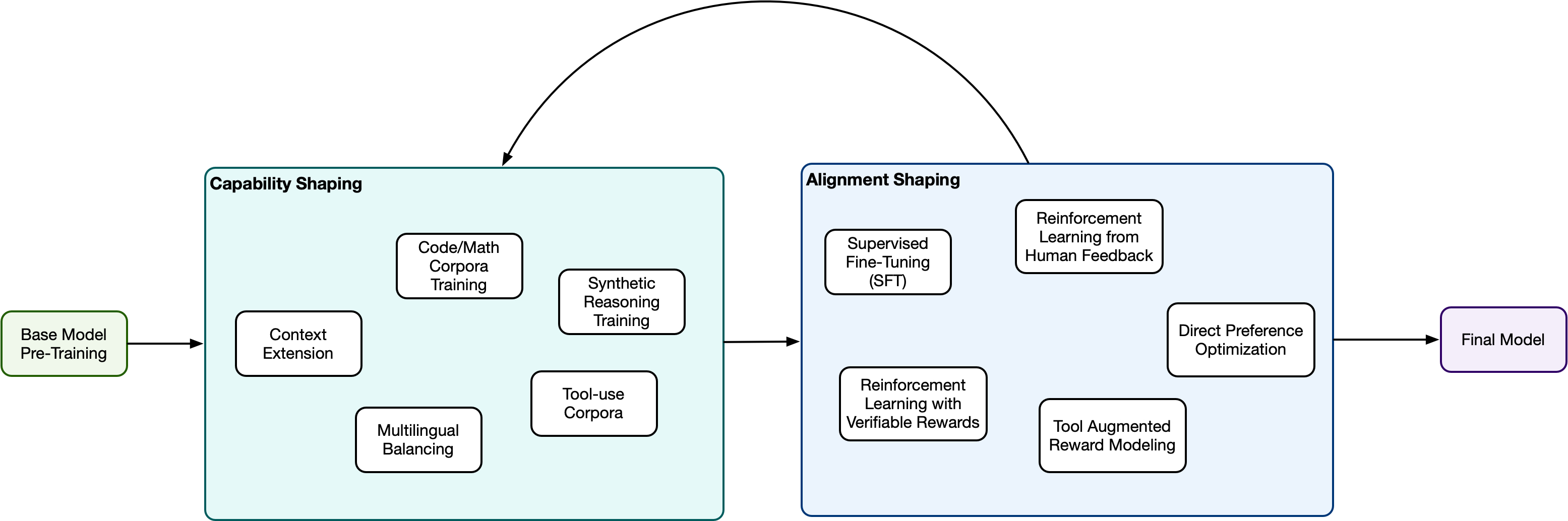
At this granularity, the internals of these stages look a bit disorganized because there is not, as yet, a definitive ordering among them. Context extension probably happens first, but beyond that, stages may be arranged in many ways, depending on project objectives and developer preferences. Some stages may not happen at all. This is especially the case for alignment shaping, where there’s likely an “exclusive or” between RLHF and DPO, which represent different approaches to solving the same problem.
We can summarize these “substages” as follows:
Capability Shaping
- Context Extension: Training interventions that increase the model’s usable context window (e.g., via positional encoding scaling or long-sequence continued training) so it can reason over longer inputs.
- Code/Math Corpora Training: Continued training on high-quality programming and mathematical datasets to improve formal reasoning, symbolic manipulation, and structured problem solving.
- Synthetic Reasoning Training: Training on model-generated or programmatically generated reasoning traces designed to induce stronger multi-step inference and chain-of-thought behavior.
- Multilingual Balancing: Reweighting and supplementing data across languages to improve cross-lingual competence and reduce performance disparities between high- and low-resource languages.
- Tool-use Corpora: Training on interaction transcripts involving external tools (e.g., search, code execution, APIs) to teach the model when and how to invoke tools effectively.
Alignment Shaping
- Supervised Fine-Tuning (SFT): Training on high-quality human-written demonstrations to condition the model toward helpful, instruction-following responses.
- Reinforcement Learning from Human Feedback (RLHF): Optimizing the model using a learned reward model trained on human preference comparisons to align outputs with human judgments.
- Reinforcement Learning with Verifiable Rewards: Applying RL where rewards are computed from objective, automatically checkable signals (e.g., correctness of math answers or unit tests).
- Direct Preference Optimization (DPO): A preference-based optimization method that directly adjusts model likelihoods to favor preferred responses without an explicit RL loop.
- Tool-Augmented Reward Modeling: Using external tools (e.g., fact-checkers, code evaluators) to help compute more reliable reward signals during alignment training.
Capabilities, Alignment, Intellect, Will
A helpful way to think about the human mind is that it has something that we could call the “intellect,” which is concerned with understanding the world, and something else called the “will” which is drawn to and chooses good things, as identified by the intellect. These two faculties of the mind are distinguishable but fundamentally intertwined, working together to allow a human to function. Thinking in these terms, it seems clear that “capabilities” and “alignment” aren’t cleanly separable notions - the intellect and the will function together. This would suggest that you can’t just “bolt on” alignment and expect to get an AI that works like a human. The “backward edge” from alignment to capability shaping captures some of the blurring between these steps, but probably still assumes too much separation. However, as a summary of the current state of AI training, the above seems to be a reasonable guide.